The Strange History of Computer Vision: How Computers Learned to See

Billy F
The setup looked like a low-budget science fiction set: a cat, anesthetized and facing a projection screen, sat with a tungsten microelectrode threaded into its visual cortex.
The electrode was the invention of one David Hubel, rigged up during his time in the army. The projection screen was a bedsheet draped over exposed ceiling pipes. In 1959, he and his research partner, Torsten Wiesel, sat in what Hubel later described as "a dark and dingy inner windowless room" in the basement of Johns Hopkins' Wilmer Institute, observing the cat.
The goal was straightforward. Project visual stimuli onto the screen, record which neurons fired in the cat's brain, and figure out how the visual cortex actually processes what the eyes take in. The problem was that, well, nothing was working.
Hubel and Wiesel tried dots of light. Nothing. They tried different sizes and positions of dots. Nada. They tried dark spots on light backgrounds. Zilch. In growing frustration, they waved their arms in front of the cat. They showed it magazine photos. The neuron they were recording from refused to respond to any of it. Up until that point, the researchers' only discovery: cats are gonna cat.
Then, as they swapped out one of the glass slides in the projector, something happened. The slide caught, and its edge cast a faint line across the bedsheet screen. The cat’s neuron exploded, firing wildly, like nothing they'd seen all day.
They stared at each other. Was that the slide? They moved it again. The neuron fired again. They rotated the angle of the edge slightly. The firing slowed. They rotated back. It fired again.
Hubel and Wiesel studied that single neuron for nine hours straight. When they were finally certain of what they'd found, they ran down the hallway of the Wilmer Institute, calling in colleagues, barely able to contain themselves.
What they'd discovered was that the visual cortex doesn't see the world the way a camera records it. The brain doesn't process whole images. It constructs vision from elemental features: edges, lines, orientations. Specific neurons respond only to lines at specific angles as if purpose-built. Other neurons respond only to those lines moving in specific directions. The brain assembles reality piece by piece, like a mosaic built from fragments of geometry.
Hubel and Wiesel (but not the cat, unfortunately) went on to win the Nobel Prize in 1981 for this work and a series of subsequent experiments. Their discovery became the foundation of an entirely new field. Every algorithm that has ever allowed a computer to identify an object in an image, every system that has ever flagged an anomaly on a surveillance feed, traces its conceptual lineage back to that basement, that bedsheet, and a glass slide that jammed in a projector.
The Weight of Seeing
Fast forward sixty-five years, and the descendants of Hubel and Wiesel's discovery are everywhere. Computer vision systems inspect bottles on manufacturing lines, scan luggage at airports, read license plates on highways, provide table games surveillance for casinos, and monitor camera feeds in cruise ships, stadiums, and retail chains.
But these systems produce something that the researchers in that basement never had to worry about: data. Enormous, relentless quantities of data.
A single 4K surveillance camera recording at 30 frames per second generates roughly a terabyte of data per month. A mid-sized casino might run 500 cameras. A large resort property might run several thousand. Multiply that across an enterprise, and you're looking at data volumes that start to behave less like files and more like physical mass.
The technology industry has a term for this: data gravity. The bigger the dataset, the harder, slower, and more expensive it becomes to move. Visual data is the heaviest element in the digital world. And that weight creates a fundamental engineering question that every organization deploying camera-based AI has to answer: where does the "thinking" happen?
There are two basic answers. You can send the video somewhere else to be analyzed (the cloud model). Or you can analyze it where it's captured (the on-premises model). Both work. Both involve genuinely different engineering, different trade-offs, and different physics. Understanding the difference starts with something that sounds simple but isn't: what happens to a video frame before a computer can look at it?
The Envelope vs. Origami: H.264 vs. H.265
Before any AI system can analyze a frame of video, that frame has to travel from the camera sensor to a processor. And raw video is far too large to move efficiently, so it gets compressed.
The two dominant compression standards in surveillance are H.264 and H.265, and they represent fundamentally different philosophies for shrinking visual information.
H.264 is the older standard. It's efficient and fast to decompress. Think of it like folding a photo into an envelope: the information is moderately compacted, but unfolding it is quick and straightforward.
H.265 is newer and roughly twice as efficient. It can squeeze the same visual quality into half the file size. But achieving that compression requires significantly more complex encoding. If H.264 is folding a photo into an envelope, H.265 is folding it into an origami crane. It packs far more into a smaller space, but the recipient has to spend considerably more effort unfolding it to read the message.
So, let's imagine folding a frame, a digital photograph of sorts. Actually, it’s not just any photograph. Imagine folding the very first digital photograph ever created: a grainy 176-by-176-pixel portrait of a three-month-old baby named Walden, scanned by his father in 1957.
The Baby and the Bomb Calculator
Russell Kirsch was 27 years old, a new father, and one of the few people authorized to operate the Standards Eastern Automatic Computer (SEAC), the first programmable computer in the United States. SEAC filled an entire room at the National Bureau of Standards in Washington, D.C., weighed 3,000 pounds, and had a memory of 512 words. Its primary job was serious government work: Social Security accounting, Air Force logistics, and calculations related to thermonuclear weapons.
Kirsch later admitted to "having stolen machine time from purportedly more useful products, like the thermonuclear weapons calculations." What he wanted to know was simple: what would happen if a computer could look at a picture?
He brought in a photo of his infant son Walden and mounted it on a rotating drum scanner that he and his colleagues had built. As the drum spun, a photomultiplier tube read the image through a tiny square aperture, transmitting ones and zeros to SEAC. One for white. Zero for black. The resulting image was 176 pixels on a side, about 5 centimeters square. It looked like a baby viewed through a screen door in heavy fog.
It was also the first time a computer had ever "seen" anything.
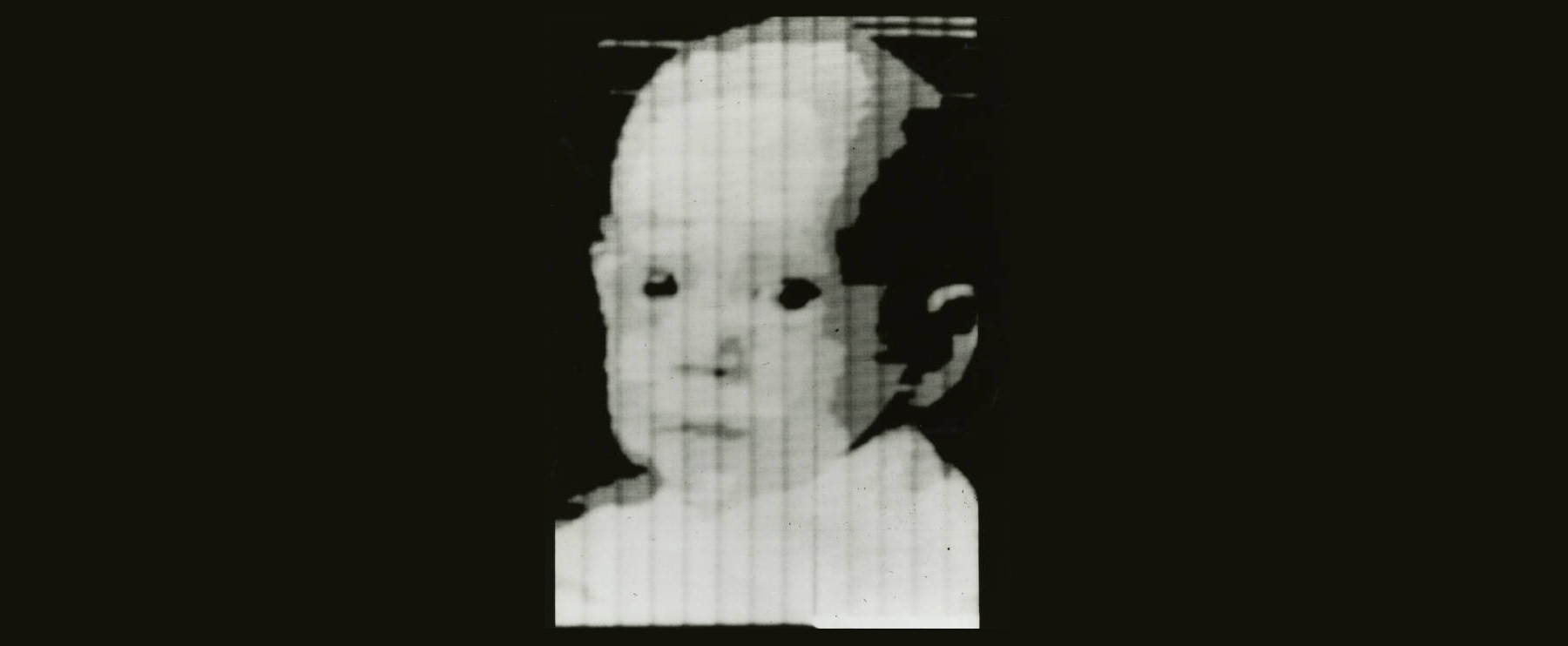
(Image of infant son of Russell A. Kirsch, first picture fed into SEAC in early 1957. Credit: National Institute of Standards and Technology Digital Archives, Gaithersburg, MD 20899.)
In 2003, Life magazine named Kirsch's baby photo one of the "100 photographs that changed the world." And it did. That grainy square of pixels is the direct ancestor of every satellite image, every medical scan, every frame of surveillance footage, and every Instagram post in existence. Russell Kirsch gave the world the pixel. His one regret, later in life, was that he'd made them square.
Unpacking the Crane: Decoding Video
Back to the origami problem. A compressed video frame, whether folded with H.264 or the tighter H.265, has to be decompressed before a neural network can analyze it. This step, called decoding, is one of the most overlooked bottlenecks in the entire vision AI pipeline.
Here's the part that may surprise some: the chip that does the AI analysis isn't the same part of the chip that unpacks the video. GPUs have a dedicated decoder, physically separate from the components that run the neural network. And that decoder has a hard ceiling. A single high-end GPU can unpack roughly twice as many simultaneous streams of 1080p video compressed with H.265 as it can streams compressed with the older H.264, because the tighter compression means less raw data flowing through the decoder per stream. Exceed those limits, and the AI side of the chip sits idle, waiting for frames to be unwrapped. It's like having ten chefs standing around a kitchen while one person struggles to unwrap all the ingredients.
This creates a real trade-off in the compression choice. H.265's tighter compression saves bandwidth (important if you're moving video across a network). But it costs more compute to decode (important if your processor is already handling dozens of camera streams). H.264's looser compression burns more bandwidth but unpacks faster. The "best" choice depends entirely on where the processing is happening and what resources are available there.
Which brings us back to the question: where does the thinking happen? But first, we need to understand what "thinking" even means for a machine looking at video.
The Baby Photo & 1.5 Ton Computer: Teaching Machines to See
For decades after Kirsch's baby photo, computers could capture and store images but couldn't tell you what was in them. Researchers tried to solve this by hand-coding the rules of vision: if these pixels form this pattern of edges, it's probably a face. If that cluster of gradients matches this template, it's probably a car. This approach worked, barely, for narrow applications. It couldn't scale.
The breakthrough required two things that didn't exist until the early 2010s: a massive collection of labeled images, and enough processing power to learn from them.
The images came from Fei-Fei Li, then an assistant professor at Princeton. In 2007, while her peers focused on refining algorithms, Li became convinced the real bottleneck was data. Children learn to see by being exposed to millions of visual examples. Why should a computer be any different?
She launched ImageNet, a project to build a database of labeled images at a scale no one had attempted. Colleagues told her it was impractical. She used Amazon's Mechanical Turk platform to crowdsource the work, ultimately enlisting 49,000 workers from 167 countries who classified over 14 million images into 22,000 categories. By 2010, she had built the largest labeled image dataset in the world and organized a competition inviting researchers to test their algorithms against it.
The processing power came from an unexpected place. In 2012, a University of Toronto graduate student named Alex Krizhevsky built a neural network and trained it on two NVIDIA GTX 580 gaming GPUs set up on a computer in his bedroom at his parents' house. The network, later named AlexNet, entered the ImageNet competition and didn't just win. It obliterated the field, achieving a 15.3% error rate while the runner-up sat at 26.2%, a gap so wide that Yann LeCun, a veteran computer vision researcher, called it "an unequivocal turning point in the history of computer vision."
AlexNet proved that if you gave a neural network enough data and enough processing power, it could learn to see. Not by following hand-coded rules, but by discovering its own features in the data, building up from edges and textures to shapes and objects. It was, in a strange way, Hubel and Wiesel's discovery in reverse. The cat experiment showed that biological vision constructs the world from simple features, layer by layer. AlexNet showed that artificial vision could do the same thing, if you gave it enough examples to learn from.
This is the moment when the question of where processing happens started to matter. Because suddenly, computers could genuinely see. And making them see required serious hardware.
The Forward Pass
When a modern vision AI system analyzes a frame of surveillance video, the process it performs is called a forward pass, or inference. Here's what's actually happening.
The decompressed frame, now a grid of pixel values thanks to Kirsch and a stolen afternoon on a bomb calculator, gets fed into a neural network. The network is structured in layers, and each layer performs mathematical transformations on the data, progressively extracting higher-level features. The first layers detect edges and simple textures. Middle layers combine those into shapes and patterns. Later layers recognize objects and scenes. If this sounds familiar, it should. It's the same hierarchy Hubel and Wiesel found in the cat's visual cortex: simple cells detecting edges, complex cells detecting motion, with each layer building on the one before it.
The entire forward pass for a single frame happens in milliseconds. But those milliseconds involve billions of mathematical operations, and the performance depends heavily on specialized hardware (GPUs optimized for parallel computation) and on the precision of the math.
High-end GPUs in data centers run calculations at high precision, producing extremely accurate results. Smaller processors designed for on-site deployment often use a technique called quantization, reducing the mathematical precision from 32-bit or 16-bit floating point down to 8-bit integers. It's like the difference between measuring with a laser and measuring with a tape measure. The tape measure loses a fraction of a millimeter, but it gives you the answer faster and with simpler equipment. For most surveillance applications, the difference in accuracy is negligible.
Two Kitchens, One Recipe: Cloud & On-Prem
Remember the weight problem. A few hundred cameras producing terabytes of data monthly, all of it needing to be decoded, preprocessed, and run through a neural network in something close to real time.
There are two fundamentally different ways to set up the kitchen.
The Cloud Kitchen. In this model, video streams leave the facility and travel across the internet to a data center, potentially hundreds of miles away. The data center houses rows of high-performance GPUs, managed by the cloud provider, available on demand. The appeal is flexibility. If you need more processing power on a Saturday night, you rent it. If traffic drops on a Tuesday morning, you scale back. You don't own any hardware, you don't maintain any servers, and you have access to the most powerful processors available.
The physics, though, impose constraints. Sending 100 cameras' worth of video across the internet requires roughly 400 megabits per second of sustained upload bandwidth, which is a dedicated enterprise fiber connection. The data has to travel from camera to ISP to internet backbone to data center, get processed, and travel back.
Even at the speed of light, this round trip introduces latency, typically 200 to 500 milliseconds under normal conditions, spiking higher during network congestion. For applications where response time is measured in seconds (retrospective review, batch analytics), this is fine. For applications where a half-second delay changes outcomes, it's a hard physical limit.
Then there's the cost of movement. Cloud providers generally don't charge to upload data, but they charge to store it, access it, and move it out. A hundred cameras generating roughly 4.3 terabytes per day creates a storage bill that can rival or exceed the compute bill itself.
The On-Premises Kitchen. In this model, the processing hardware lives in the same building as the cameras. Servers with GPUs (not to be confused with edge computing, which puts processing on or inside the camera itself) sit in a server room or closet, connected to cameras over the facility's local network.
Local networks are orders of magnitude faster than internet connections, both in how much data they can move and how quickly it arrives. A video frame traveling across a local network reaches the server in the same building almost instantaneously. That same frame traveling to a cloud data center might take a few hundred milliseconds, roughly the time between a blink starting and finishing. That gap might sound trivial to us mere human mortals, but a cheating move at a blackjack table happens in a fraction of a second. A system processing locally can flag it before the dealer pushes the cards. A system waiting on a round trip from Vegas to a data center in Virginia might flag it after the hand is already over.
The appeal is speed and predictability. Inference times are stable and fast, typically under 20 milliseconds, because the data never leaves the building. There's no internet variability, no egress fees, and no third party handling the video. For industries with strict data regulations, this matters. Video that never leaves the facility is video that can't be intercepted, subpoenaed from a third party's servers, or subjected to another jurisdiction's data laws.
The trade-off is ownership. The hardware has to be purchased, installed, powered, cooled, and eventually replaced. A rack of GPU servers consumes meaningful electricity. If a component fails, someone on-site has to fix it.
Back to the Basement
In that windowless room in 1959, Hubel and Wiesel made a discovery that rewrote our understanding of sight. The brain doesn't record the world passively, like a camera storing footage. It actively constructs a version of reality, assembling it from fragments: an edge here, a moving line there, layers of increasing complexity building upward until the raw signal from the retina becomes a face, a room, a threat.
Sixty-five years later, every neural network processing a surveillance camera feed is doing a version of the same thing. First layers detect edges. Middle layers detect shapes. Final layers detect meaning. The math is different. The substrate is silicon instead of neurons. But the architecture, a hierarchy of feature detectors building from simple to complex, is the one that fired in a cat's visual cortex when a glass slide jammed in a projector.
The question of where that processing happens (in a data center reached by fiber optic cable, or on a server in a closet down the hall from the cameras) is an engineering decision with real consequences for speed, cost, security, and capability. But the underlying process is the same. Light hits a sensor. The signal gets compressed, transmitted, decoded. A network of artificial neurons constructs meaning from raw data, edge by edge, layer by layer.
Russell Kirsch asked the question in 1957: what would happen if computers could look at pictures? We've been answering it ever since.
Sources & Further Reading
Hubel, D.H. & Wiesel, T.N. (1959). Receptive fields of single neurones in the cat's striate cortex. Journal of Physiology, 148(3), 574-591. JHU Hub: How the accidental discovery led to a Nobel Prize
Kirsch, R. (1957). First digital image, created at the National Bureau of Standards using the SEAC computer. NIST: First Digital Image
Krizhevsky, A., Sutskever, I., & Hinton, G.E. (2012). ImageNet Classification with Deep Convolutional Neural Networks. NeurIPS. Computer History Museum: AlexNet Source Code Release
Li, F.F. et al. ImageNet: A Large-Scale Hierarchical Image Database. ImageNet | Wikipedia: ImageNet History
NVIDIA. A100 Tensor Core GPU Architecture Whitepaper. NVIDIA A100 Whitepaper (PDF)
e-con Systems. A Comprehensive Study: H.264 vs H.265 Compression in Embedded Vision. H.264 vs H.265 Analysis
Hero image: National Institute of Standards and Technology Digital Archives, Gaithersburg, MD 20899

Billy F
Billy F. is Business Operations & GTM Systems Lead at EagleSight.ai.